Research Narrative
This section is organized as reading logs rather than as project cards. The emphasis is on why a reading path started, what changed in my understanding, and what open questions remained after each cluster.
DAS Research Log: From Ethereum Blobs to Coded Distributed Arrays
DAS Research Log: From Ethereum Blobs to Coded Distributed Arrays
This research log is my own path through Data Availability Sampling. It starts from the basic question of why a blockchain needs data availability at all, then moves into Ethereum's blob roadmap, the network-layer problem behind DAS, and finally the idea that became our first accepted paper: Coded Distributed Arrays.
I wrote this because I do not want the topic to appear only as a publication result. For me, the important part is the path:
- understanding why full replication does not scale;
- seeing why Ethereum moved from
calldatato blobs; - realizing that DAS is not only a cryptographic problem, but also a peer-to-peer network problem;
- and then asking whether we can keep RDA's robustness while reducing its replication cost.
The log is organized into four parts:
- What is DAS?
Why simple splitting is not enough, how erasure coding changes the availability question, and why sampling can replace full download. - DAS on Ethereum
How rollups use Ethereum for data publication, whatEIP-4844changed, and how PeerDAS assigns blob custody through data columns. - Network Layer for DAS: RDA
Why DHT and gossip-based designs are fragile or slow under adversarial conditions, and how Robust Distributed Arrays give a cleaner P2P structure. - Network Layer for DAS: CDA
How our Coded Distributed Array direction uses RLNC and homomorphic KZG commitments to reduce storage and propagation overhead while keeping the grid-based security intuition.
What is Data Availability Sampling?
What is Data Availability Sampling?
The first question I had to settle was simple:
If a block producer claims that some data exists, how can the rest of the network know that the data is really available without forcing every node to download everything?
In a traditional blockchain, the answer is full replication. Every full node downloads the whole block, verifies it, and stores enough history to keep the system independently checkable. That model is clean and secure, but it does not scale well when blocks become large.
For rollups and data-heavy blockchain systems, this becomes a bottleneck. The data may only be needed for verification during a limited window, but the network still pays the cost of distributing it broadly. So the goal of Data Availability Sampling is not to make data disappear. The goal is to make enough of the data checkable so that the network can be confident the full data can be recovered.
Why simple splitting fails
A naive idea is to split the block into many pieces and let different nodes store different pieces. At first glance, that seems like sharding:
- each node stores less;
- the whole network collectively stores the block;
- and validators no longer need to download everything.
The problem is that plain splitting is fragile. If even one important piece disappears, the original block may no longer be reconstructible. An attacker does not need to hide the whole block. It may be enough to hide a small part that everyone needs.
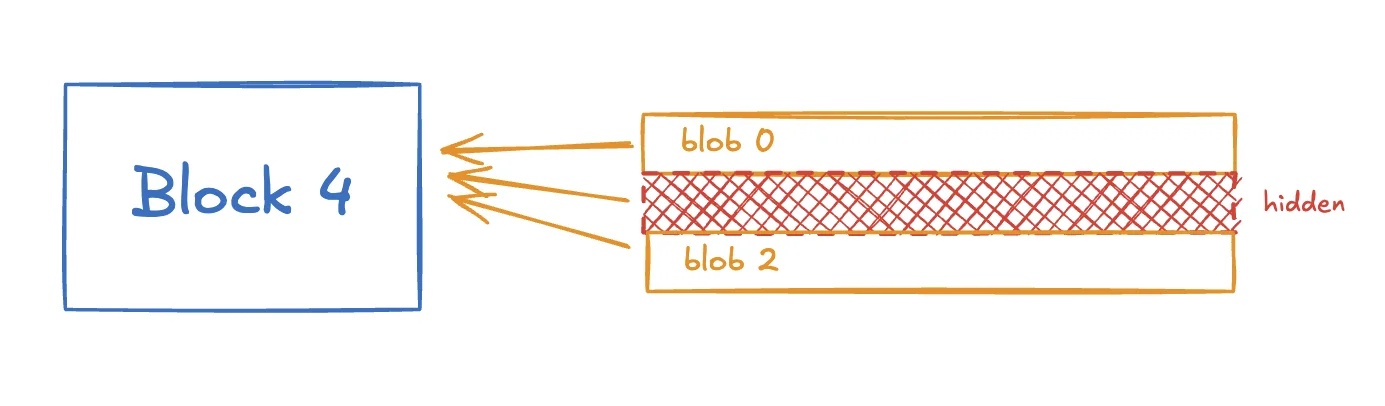
That is why DAS starts with a stronger primitive: erasure coding.
Erasure coding
Erasure coding changes the availability problem. Instead of storing only the original pieces, the publisher expands the data into a larger coded form.
The intuition is:
- start with
koriginal pieces; - encode them into
ncoded pieces; - make the code so that any sufficiently large subset can reconstruct the original data.
So the network no longer depends on every exact original piece staying online. It only needs enough coded pieces to survive.
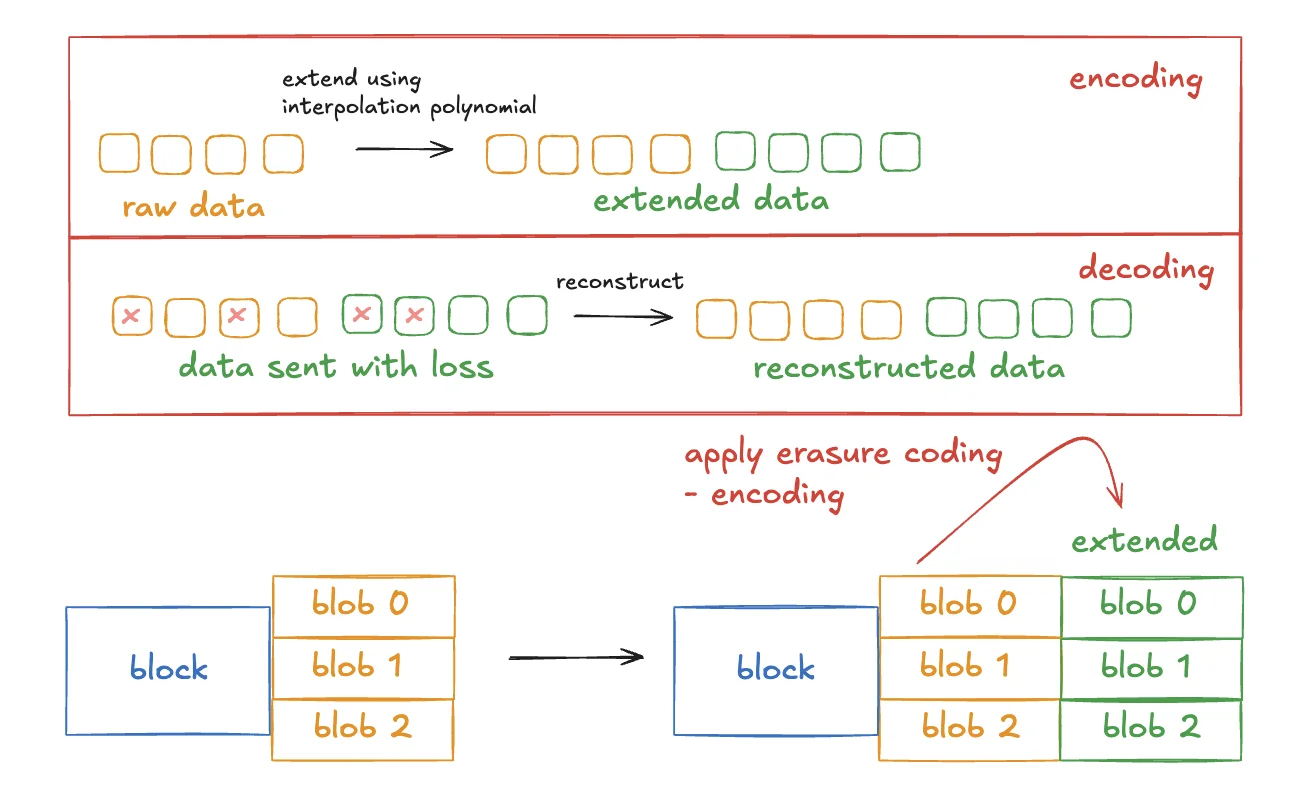
This is the core shift. Without erasure coding, the question is:
Is every original piece still there?
With erasure coding, the question becomes:
Are enough coded pieces still available to reconstruct the original data?
That second question is what makes sampling possible.
Sampling instead of full download
Once the data is erasure-coded, a verifier does not need to download the whole encoded block. It can randomly sample a small number of positions. If the block producer has hidden enough data to make the block unrecoverable, random samples should hit the missing region with high probability.
For the simple 1D intuition, suppose the data is expanded from k pieces into 2k coded pieces.
To make reconstruction impossible, an attacker must hide more than half of the coded data.
If a verifier samples n independent positions, the chance that every sample misses the hidden half is roughly:
(1/2)^n
So the detection probability is:
1 - (1/2)^n
With only 20 samples, this is already extremely close to 1.
That is the appeal of DAS:
- the verifier downloads only a tiny part;
- the network still gets strong confidence that the data is available;
- and block size can grow without making every validator download the full block.
Why the network layer matters
Sampling sounds simple in the abstract, but a real blockchain has to answer a harder question:
Where does a verifier send a sampling request, and what happens if the peer responsible for that sample is offline or malicious?
This is why DAS is not only about erasure coding or KZG commitments. Those are necessary, but not enough. The network must also decide:
- how coded pieces are assigned to peers;
- how samplers discover peers that store the needed data;
- how data is propagated quickly enough before validators attest;
- and how the system remains robust when some peers refuse to serve data.
That is the bridge from the cryptographic idea of DAS to the networking problem that eventually led us to RDA and CDA.
DAS on Ethereum
DAS on Ethereum
Ethereum's data availability problem is easiest to understand through rollups. Rollups execute transactions offchain, but they still need to publish enough data to Ethereum so that outsiders can reconstruct and verify the rollup state transition.
If that data is missing, users cannot independently check the rollup. For optimistic rollups, missing data weakens fraud proofs. For validity rollups, missing data makes it harder for outsiders to reconstruct the state transition behind the proof.
So the basic rule is:
Ethereum does not need to execute all rollup transactions, but it must make the rollup data available long enough for verification.
From calldata to blobs
Before EIP-4844, rollups commonly published data through calldata.
That worked, but it was a bad fit.
calldata belongs to the execution path.
It is attached to normal transactions, processed by the execution layer, and kept permanently in Ethereum history.
Rollup batch data does not need that treatment.
It mainly needs temporary availability.
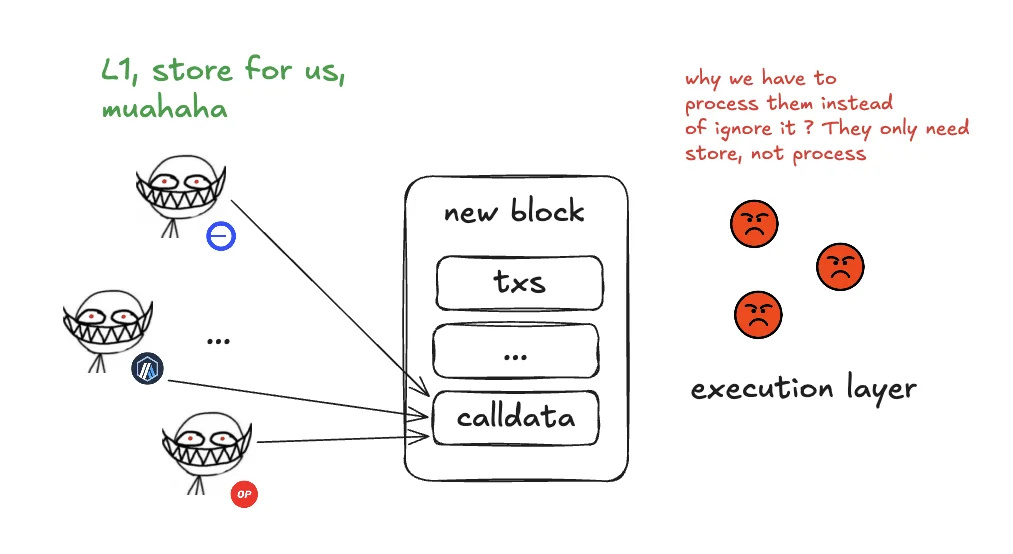
EIP-4844, also called Proto-Danksharding, introduced blobs as a separate data lane for rollups.
The key change is that blob data is handled by the consensus layer and kept for a bounded availability window, instead of being permanent execution-layer data.
This gives Ethereum a cleaner separation:
- execution data stays on the execution path;
- rollup data goes into temporary blobs;
- block commitments refer to blob data without putting all blob bytes into the execution payload.
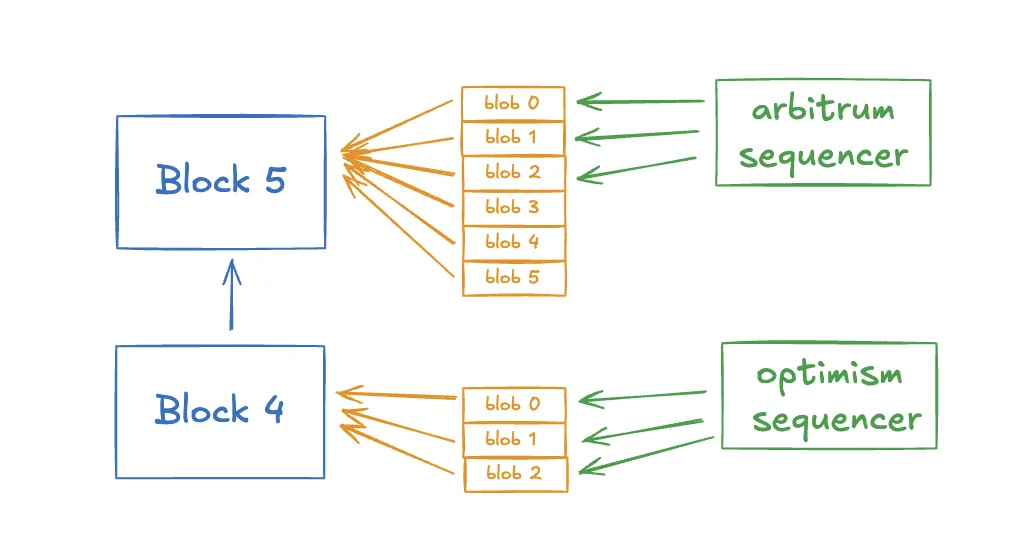
Before a node accepts a block with blobs, it must be able to download and verify the associated blob data. The block contains blob commitments, and the node checks the blob data against those commitments.
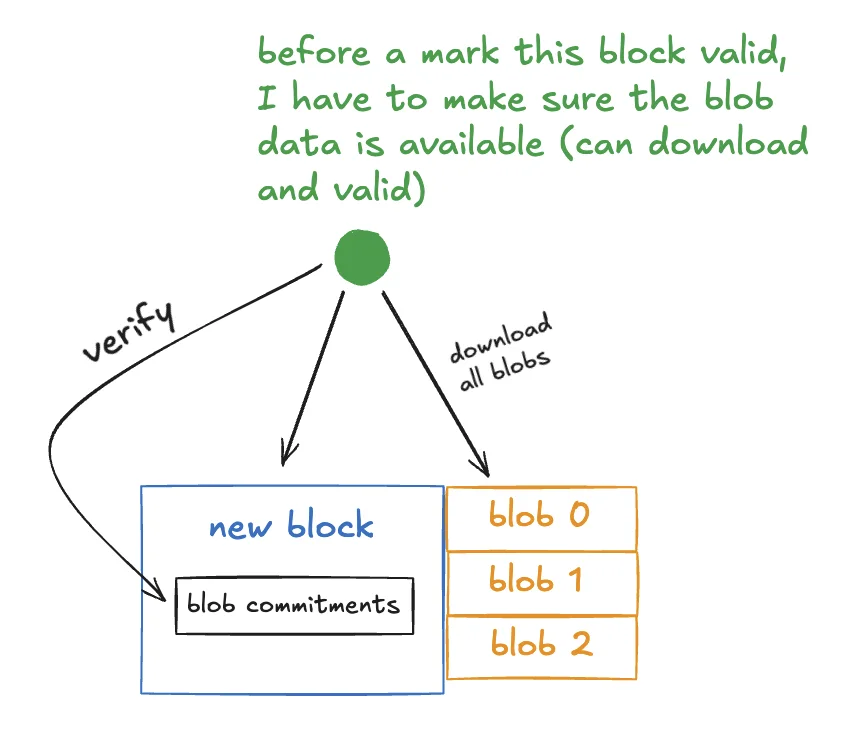
Proto-Danksharding solved an important part of the problem:
- rollup data no longer has to live forever as
calldata; - Ethereum gets a dedicated temporary data lane;
- L2s get cheaper and more appropriate data publication.
But it did not yet solve the full scaling problem. If every consensus node still downloads every blob, then blob capacity is limited by what normal nodes can handle. Increasing blob count too far would push bandwidth requirements upward and weaken decentralization.
That leads to the next step: PeerDAS.
PeerDAS: assigning data columns
PeerDAS tries to move Ethereum from full blob download toward custody and sampling. Instead of every node storing every blob, blob data is erasure-coded and organized into data columns.
In the PeerDAS model:
- blob data is encoded into a larger structure;
- that structure is divided into columns;
- each node is assigned some columns to custody;
- nodes also sample additional columns from peers before accepting a block.
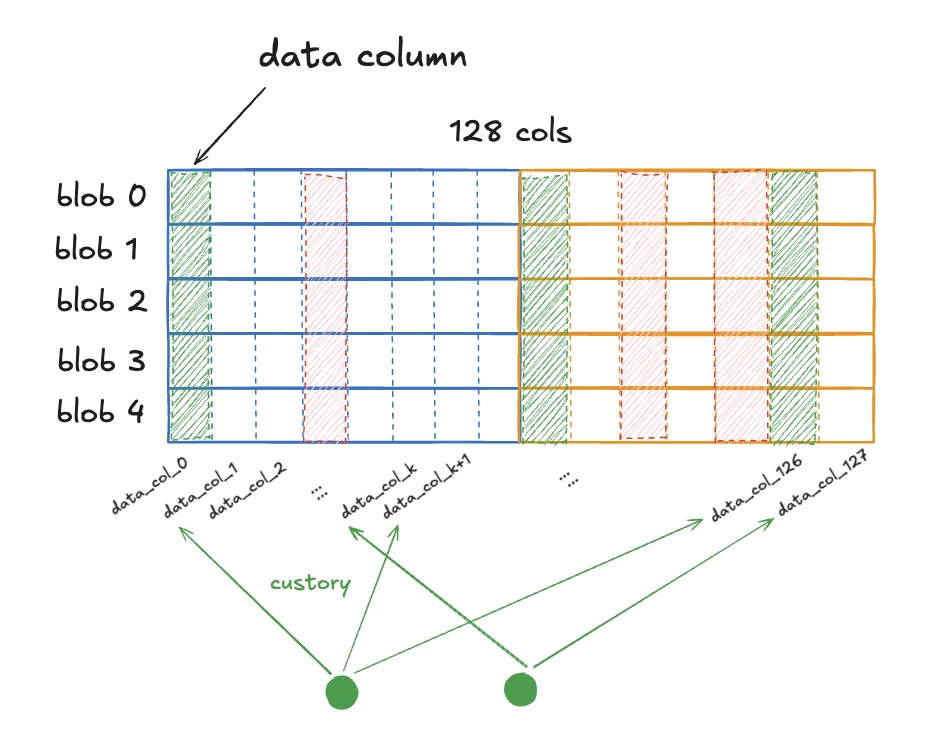
This changes the responsibility of a node. The node no longer has to store all blob data. It must store its assigned custody columns and sample enough other columns to gain confidence that the full data is available.
The high-level flow is:
- the block producer prepares blob data and commitments;
- data is propagated into column sidecar topics;
- each node downloads and stores its assigned columns;
- each node samples additional columns without keeping all of them;
- if enough samples succeed, the node can accept that the block data is available.
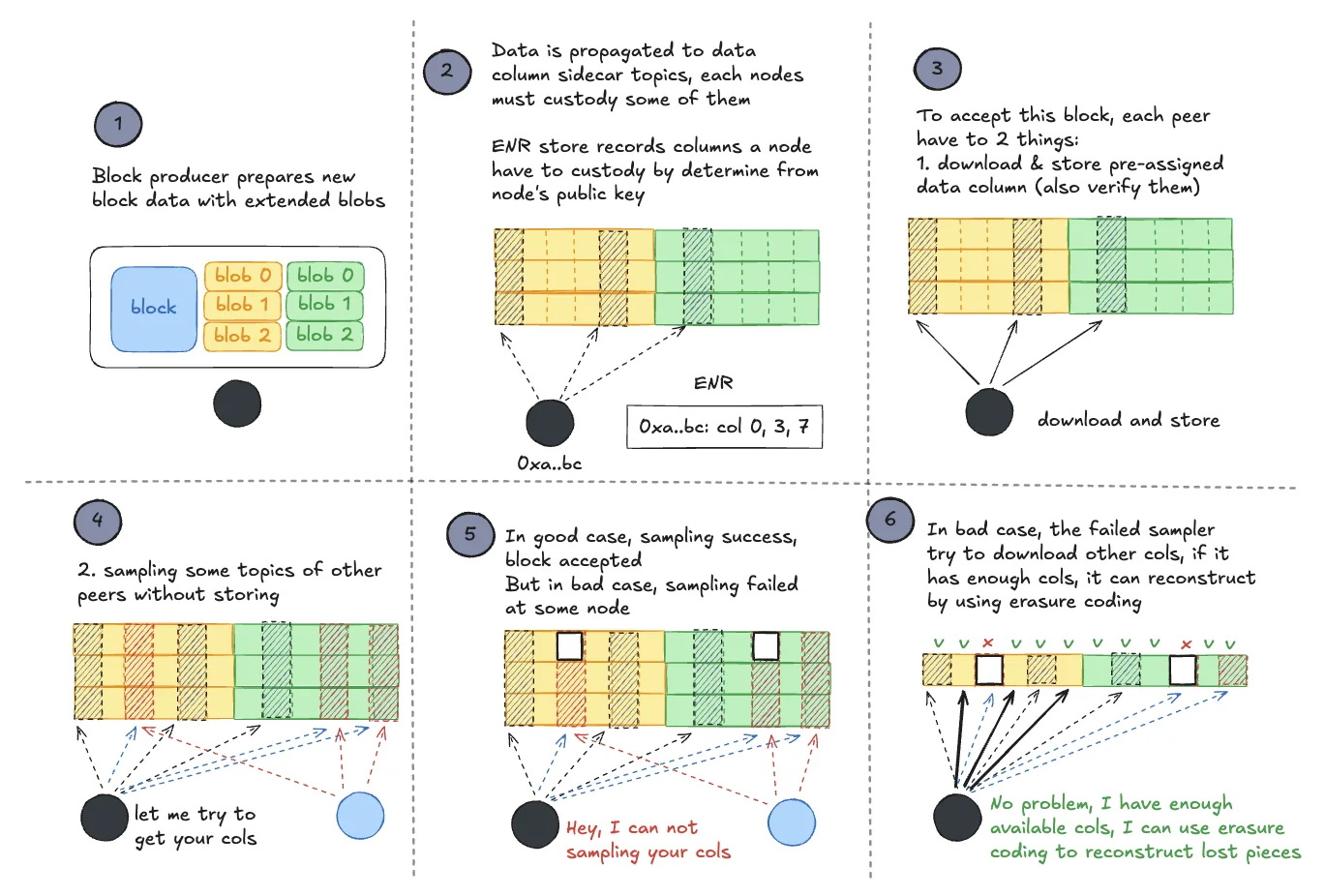
This is a major improvement over full download. It lets Ethereum increase blob throughput without forcing every validator to carry the entire data burden.
But PeerDAS also exposes the next bottleneck. Once sampling becomes a network request, the quality of the peer-to-peer layer matters. If retrieval is slow, unstable, or easy to attack, then the cryptographic sampling guarantee is not enough.
That is where my focus moved next. The deeper problem became:
How should a DAS network store, route, and recover coded data under Byzantine behavior?
Network Layer for DAS: RDA
Network Layer for DAS: RDA
After understanding PeerDAS, I realized that DAS has two layers that are easy to mix together.
The first layer is the data layer:
- erasure coding;
- commitments;
- sampling probability;
- proof verification.
The second layer is the network layer:
- where data pieces are stored;
- how peers discover the right holders;
- how fast data is disseminated;
- and how the system behaves when some peers are Byzantine.
Most explanations of DAS emphasize the first layer. But in a real blockchain, the second layer is just as important. A sample is only useful if the verifier can actually retrieve it from the network in time.
Why DHT and gossip are not enough
Distributed Hash Tables are attractive because they give an efficient way to find data in a large peer-to-peer network. Ethereum already uses peer discovery ideas related to this world. So it is natural to ask whether DHT-style retrieval can solve DAS sampling.
The problem is adversarial behavior. DHT retrieval often depends on multi-hop routing and neighborhood structure. If malicious peers can influence the path or surround a key space region, they can make a sample hard to retrieve even when the data exists somewhere else.
GossipSub has a different tradeoff. It is useful for spreading messages, but it is not a precise retrieval mechanism. For very large encoded data, relying only on gossip can create propagation delay and duplicated traffic.
So the network-layer problem is a tradeoff:
- DHT-style retrieval is efficient but fragile under Byzantine routing;
- gossip is robust for broadcast but expensive for large data dissemination;
- centralized builder-heavy approaches can be fast but push responsibility toward a stronger actor.
This is why RDA is interesting. It gives a cleaner network structure for DAS.
Robust Distributed Arrays
Robust Distributed Arrays, or RDA, organize the peer-to-peer network as a grid.
Each node is assigned to one row and one column.
Instead of knowing the whole network, a node only needs to know peers in its own row and column.
The data is also organized by columns. A block is divided into chunks, and each chunk is assigned to a network column. All nodes in that column store the same chunk.
This gives RDA a very simple sampling path:
- identify which chunk contains the sampled symbol;
- find the network column responsible for that chunk;
- ask nodes in that column;
- as long as one honest node in the column has the chunk, the sample can be served.
That is the power of RDA. It turns sampling into a mostly one-hop operation and avoids the uncertainty of multi-hop DHT retrieval.
Why RDA is robust
RDA is pessimistic in a useful way. It does not need an honest majority in the whole network. Instead, it needs enough honest nodes distributed so that every important column has at least one honest node.
Once that condition holds, data retrieval is simple. If a malicious node refuses to answer, the sampler can ask other nodes in the same column. The grid gives a clear recovery route.
This makes RDA much easier to reason about than a DHT path under adversarial conditions. The storage location is explicit. The retrieval path is short. The security argument is cleaner.
The cost of RDA
The cost is replication.
Because every node in a column stores the full assigned chunk, the same data is duplicated many times.
If a network has 5000 nodes and the node matrix has 100 columns, then each column has roughly:
5000 / 100 = 50
nodes.
That means the chunk assigned to that column is replicated around 50 times.
This is robust, but expensive.
The CDA paper frames this as the key limitation:
RDA gives an excellent sampling path, but full-column replication is too strong.
That observation became the starting point for our direction. Instead of discarding RDA's grid structure, we asked a narrower question:
Can we keep the robust grid idea, but reduce how much duplicate data each column must store and transmit?
For visualization of the RDA direction and the early CDA motivation, the shared slide deck is still useful: Open PDF visualization
Network Layer for DAS: Coded Distributed Array
Network Layer for DAS: Coded Distributed Array
Our solution starts from a simple disagreement with RDA's storage rule.
RDA says:
Put the full chunk in every node of the destination column.
CDA asks:
What if nodes in that column store different coded pieces instead?
That is the main idea behind Coded Distributed Arrays.
We keep the grid intuition from RDA, but we avoid full-column replication by applying Random Linear Network Coding, or RLNC, at the data-piece level.
The intuition behind RLNC
RLNC is useful because it lets data be recovered from enough random linear combinations.
Instead of storing exact copies of a piece, nodes can store coded pieces. If a sampler later gathers enough independent coded pieces, it can reconstruct the original symbol or chunk.
This gives CDA a different tradeoff from RDA:
- RDA downloads from one honest node that stores a full chunk;
- CDA may need to collect several smaller coded pieces;
- but each stored piece is much smaller, and the column no longer needs full replication everywhere.
So CDA accepts a more involved reconstruction path in exchange for lower storage and propagation cost.
CDA data encoding
The paper describes CDA as an extra RLNC layer on top of the erasure-coded block.
At a high level:
- start with a raw block;
- apply 2D Reed-Solomon erasure coding to get an extended block;
- divide each cell into smaller fragments;
- generate an RLNC-coded piece from those fragments using a random coding vector.
The result is not just one encoded block. Different coded versions can be generated from the same extended block by using different random coding vectors.
That matters because the network can store diversity instead of duplication. Nodes in the same custody column do not all need to hold the same full chunk. They can hold different coded versions that collectively support reconstruction.
Commitment and verification
The hard part is not only coding the data. The verifier must still know that a coded piece is valid.
In normal DAS, KZG commitments let a verifier check that a sampled cell belongs to the committed blob. CDA still needs that property, but RLNC introduces linear combinations of fragments.
The key observation in the paper is that KZG commitments are additively homomorphic. That means a commitment to a linear combination can be derived from the same linear combination of commitments.
So if a coded piece is built with coding vector g, the corresponding commitment and opening can be combined with the same vector.
This lets a verifier check a coded piece directly, without reconstructing the original symbol first.
This is important because CDA would not be useful if every sample required full reconstruction before verification. The commitment layer has to preserve both:
- position binding: the piece belongs to the claimed position;
- code binding: the piece is consistent with the committed encoded data.
CDA network layer
CDA keeps the grid topology because the grid is what makes RDA's retrieval path clean.
Nodes are assigned to cells in a k1 × k2 network matrix.
Each node maintains peers in its row and column.
Bootstrap nodes help new nodes discover the network and synchronize historical data.
The difference is what happens inside a custody column.
STORE
When a block is published:
- the publisher splits the extended block into chunks;
- each chunk is assigned to a destination network column;
- nodes receiving that chunk generate RLNC-coded versions;
- coded chunks are sent to peers in the destination column;
- each receiver verifies the coded pieces and stores valid ones.
Compared with RDA, the column stores coded diversity rather than repeated full copies. Each node stores only a coded version, which is smaller than the full chunk.
GET
When a sampler wants a symbol:
- it identifies which chunk and custody column contain the target position;
- it asks the relevant peers for RLNC pieces;
- an honest peer gathers enough valid coded pieces from the column;
- the symbol is decoded and returned to the sampler;
- if the direct path fails, the sampler can fall back through bootstrap nodes, similar to RDA.
This is the central CDA tradeoff. Sampling may require more than one coded piece, but each piece is much smaller and the network stores much less duplicated data.
What CDA improves
The paper evaluates CDA against RDA under the same style of security constraints. The main result is that CDA keeps the grid-based robustness intuition while reducing several costs:
- around
5xlower storage/replication cost; - around
2xlower propagation cost; - around
1.4xlower historical synchronization cost for new nodes.
The reason is straightforward. RDA uses replication to make retrieval simple. CDA uses coding to make replication cheaper.
This does not mean CDA is free. Its main tradeoff is that symbol reconstruction may require downloading multiple coded pieces from different nodes. That can affect sampling latency, and the paper leaves real-network latency evaluation as future work.
But for me, this is exactly why CDA is interesting. It shows that the network layer of DAS is still open. There is room to design systems that are not only cryptographically secure, but also more efficient in how they store, disseminate, and recover data across a real peer-to-peer network.
That is the research direction I want to keep exploring.